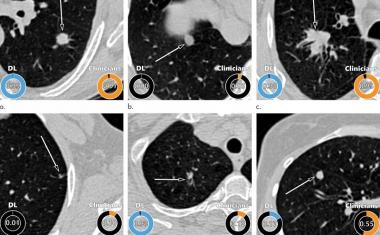
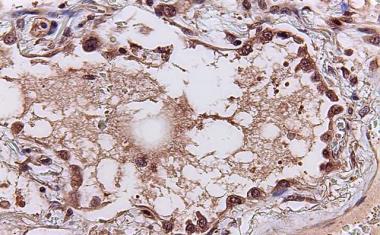
一项由芝加哥大学研究人员领导的新研究表明深度学习根据大量癌症遗传和组织组织学数据训练的G模型可以很容易地识别提交图像的机构。模型,使用机器学习“教”自己如何识别某些癌症特征的方法,最终使用提交网站作为预测患者结果的捷径,将他们与来自同一地点的其他患者放在一起,而不是依赖于单个患者的生物学。这反过来可能导致对来自种族或少数民族群体的患者的偏见和错失治疗机会,这些人可能更有可能在某些医疗中心有代表,并且已经难以获得护理。
“我们在深入学习模型开发中确定了一个耀眼的洞穴,这使得某些地区和患者群体更容易被包含在不准确的算法预测中,”乌克西哥助理助理助理教授博士,博士,博士,博士,博士助理医学与共同高级作者。
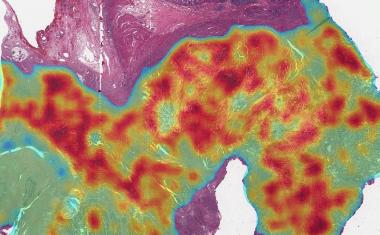
治疗癌症患者的第一步之一是肿瘤的活组织检查或小组织样本。将一个非常薄的肿瘤切片固定在玻璃载玻片上,玻璃载玻片染色,用多彩多姿的染料染色,用于通过病理学家进行审查以进行诊断。然后可以通过使用扫描显微镜来创建数字图像以进行存储和远程分析。虽然这些步骤主要是跨病理实验室的标准标准,但是染色的颜色或量和成像设备中的颜色或量的微小变化可以在每个图像上创建唯一的签名,如标签。这些特定于位置的签名对于肉眼不可见,但很容易被强大的深度学习算法检测到。
广告

广告

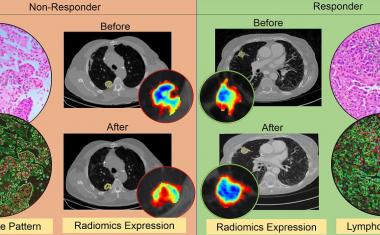
这些算法有可能成为允许医生快速分析一个有价值的工具肿瘤以及指导治疗选择,但这种偏见的引入意味着模型并不总是基于其在图像中看到的生物特征进行分析,而是基于提交站点之间的差异产生的图像伪影。
Pearson和他的同事研究了从癌症基因组地图集的数据培训的深度学习模型的表现,是癌症遗传和组织数据的最大存储库之一。这些模型可以预测生存率,基因表达模式,突变,以及更多来自组织的突变组织学,但是这些患者特征的出现频率根据提交图像的机构而有很大的不同,并且该模型通常默认采用“最简单”的方法来区分样本——在本例中,是提交的站点。
例如,如果A医院主要为富裕的患者提供更多的资源和更好的治疗,那么该医院提交的图像通常会表明更好的患者预后和生存率。如果B医院的服务对象是那些难以获得高质量医疗服务的弱势群体,那么该网站提交的图片通常会预测更糟糕的结果。
研究小组发现,一旦确定了哪个机构提交了图像的模型,他们倾向于使用它作为图像的其他特征,包括祖先。换句话说,如果染色或成像幻灯片的技术看起来被提交的医院,模型预测更好的结果,而他们会预测更糟的结果如果它看起来就像一个图像从医院B。相反,如果所有的病人在医院B生物学特性基于遗传学表明一个更糟糕的预后,算法将把更坏的结果与B医院的染色模式联系起来,而不是它在组织中看到的东西。
“算法旨在找到一种信号来区分图像,它通过识别该网站而懒惰地进行,”Pearson说。“我们实际上希望了解肿瘤内的生物学更容易倾向于治疗或早期转移性疾病,因此我们必须从真正的生物信号中解开该网站特异性数字组织学签名。”
避免这种偏见的关键是仔细考虑用于训练模型的数据。开发人员可以确保不同的疾病结果均匀地分布在训练数据中使用的所有站点,或者当结果分布不平等时,通过在训练或测试模型时隔离某个站点。结果将产生更准确的工具,可以让医生得到他们需要的信息,以快速诊断和计划治疗癌症患者。
”的承诺人工智能“Pearson说,是能够为更多人带来准确和快速的精确健康的能力。”为了满足我们社会的脱落成员的需求,我们必须能够开发有能力并做出相关预测的算法为了所有人。”
该研究发表于自然通讯.
来源:芝加哥大学