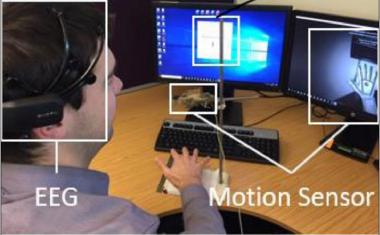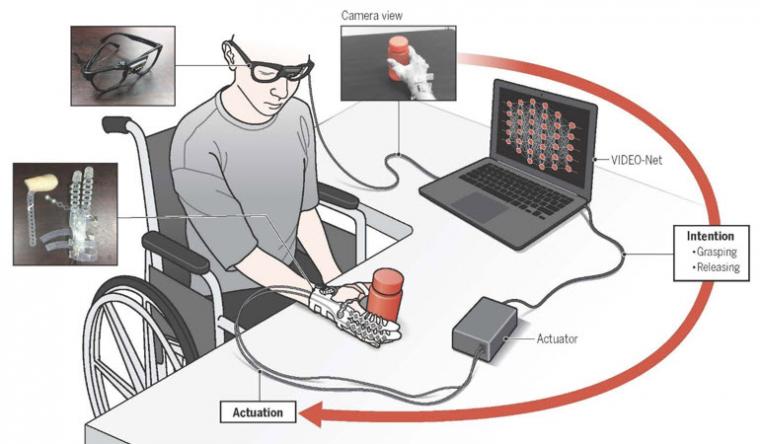
他们开发了一种基于机器学习算法的方法,该算法利用第一人称视角(first-person-view)来预测可穿戴式手机器人的用户意图。它们的开发基于以下假设:用户意图可以通过用户手臂行为和手-物交互的集合来推断。
本研究使用的机器学习模型——基于自我中心视角的视觉意图检测网络(Vision-based Intention Detection network, VIDEO-Net)就是基于这个假设而设计的。视频网络由时空网络组成,其中时空网络用于识别用户手臂行为,空间网络用于识别手-物交互。
一名脊髓损伤患者戴着一款柔软的可穿戴手机器人——Exo-Glove Poly II,在没有任何额外帮助的情况下,成功地拾取和放置各种物品,并完成日常生活中必不可少的活动,如喝咖啡。他们的发展是有利的,因为它检测用户的意图,而不需要任何个人对个人校准和额外的行动。这使得可穿戴式手机器人能够与人类进行无缝交互。
广告

广告

这个系统是如何工作的?
该技术的目的是利用安装在眼镜上的第一人称摄像机,预测用户的意图,特别是对目标物体的抓取和释放意图。(类似谷歌Glass的东西将来也可以使用)。设计了一种基于深度学习的算法VIDEO-Net,该算法基于用户手臂行为和手-物交互来预测摄像机的用户意图。使用Vision,环境和人体运动数据被捕获,用于训练机器学习算法。
我们没有使用通常用于残障人士意图检测的生物信号,而是使用一个简单的相机来发现用户的意图。不管这个人是不是在试图抓住。这是因为目标用户能够移动他们的手臂,但不能移动他们的手。我们可以通过观察手臂的运动和物体与手的距离来预测用户的抓取意图,并使用机器学习来解释观察结果。
谁能从这项技术中受益?
如前所述,该技术通过人类手臂行为和手-物交互来检测用户意图。这项技术可以被任何手失去行动能力的人使用,如脊髓损伤、中风、脑瘫或任何其他损伤,只要他们可以自主移动手臂。用视觉来估计人类行为的概念
限制和未来的工作是什么?
大多数的限制来自使用单目相机的缺点。例如,如果一个目标对象被另一个对象遮挡,该技术的性能就会下降。此外,如果用户的手势不能在相机场景中看到,这项技术是不可用的。为了克服这些缺点所造成的通用性不足,需要对算法进行改进,结合其他传感器信息或现有的其他意图检测方法,如使用肌电图传感器或跟踪眼球注视。
在日常生活中使用这项技术,你需要什么?
如果要将该技术应用到日常生活中,就需要安装有驱动模块的可穿戴式手形机器人、安装有计算装置的眼镜和装有摄像头的眼镜。我们的目标是减小计算设备的尺寸和重量,使机器人在日常生活中可以携带使用。到目前为止,我们可以找到满足我们要求的紧凑的计算设备,但我们希望能够执行深度学习计算的神经形态芯片将会商业化。
来源:首尔国立大学