人类天生就是有创造力的工具使用者。当我们需要钉钉子而没有锤子时,我们很容易就会意识到,我们可以用一个沉重的、扁平的物体,比如一块石头来代替它。当我们的桌子摇摇晃晃的时候,我们很快发现可以在桌腿下面放一叠纸来稳定它。但是,尽管这些行为对我们来说是如此自然,它们却被认为是高智商的标志——只有少数其他物种能以新颖的方式使用物体来解决问题,而且没有一种能像人类那样灵活自如。是什么为我们以这种方式使用对象提供了这些强大的功能?
广告

广告

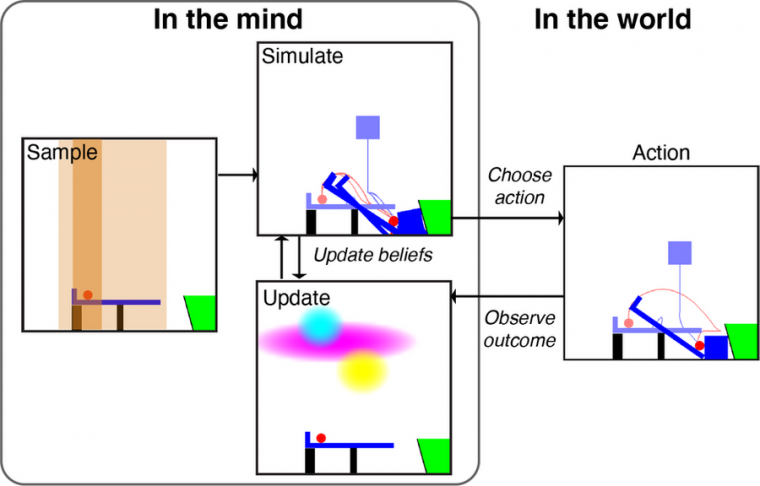
该团队假设人们在解决这些难题时依赖于三种能力:一种引导人们行动的先验信念,能够想象他们行动的效果,以及一种机制,能够快速更新他们关于什么行动可能提供解决方案的信念。他们建立了一个实例化这些原则的模型,称为“样本、模拟、更新”或“SSUP”模型,并让它发挥同样的作用游戏随着人们。他们发现,SSUP解决每个谜题的速度和方式与人类相似。另一方面,一个流行的深度学习模型可以很好地玩雅达利游戏,但没有相同的物体和物理结构,无法将其知识归纳到没有直接训练的谜题中。
本研究为研究和形式化支持人类工具使用的认知提供了一个新的框架。团队希望扩展这个框架不仅研究工具的使用,而且人们可以创建新问题,创新工具和人类如何传递这些信息从简单的物理工具来构建复杂的对象像电脑或飞机,现在我们日常生活的一部分。
Kelsey Allen是麻省理工学院计算认知科学实验室的一名博士生,对于虚拟工具游戏如何支持其他对工具使用感兴趣的认知科学家感到兴奋:“在这个领域有太多的东西需要探索。我们已经开始与多个不同机构的研究人员合作项目,从研究游戏的趣味性,到研究身体化如何影响无实体的物理推理。我希望认知科学界的其他人能将这款游戏作为一种工具,更好地理解物理模型与决策和计划之间的相互作用。”
麻省理工学院(MIT)计算认知科学教授约书亚•特南鲍姆(Joshua Tenenbaum)认为,这项工作不仅有助于理解人类认知和文化的一个重要方面,也有助于理解如何在机器中构建更像人类的智能。”人工智能研究人员已经非常兴奋的潜力强化学习(RL)算法从试错学习经验,和人类一样,但真正的试错学习人类受益于展开在只有少数的实验中——不是数百万或数十亿的经历,在今天的RL系统,”特南鲍姆说。游戏“虚拟工具允许我们研究这个快速和更自然的试错学习人类,事实上,SSUP模型能够捕捉快速学习动力我们看到人类表明它也可能方向RL的新人工智能方法,可以从他们的成功,他们的失败,他们的失误和人类一样迅速灵活。”
来源:麻省理工学院