广告

广告

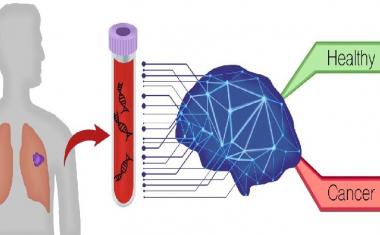
“目前,初步诊断是通过纸笔筛选测试进行的,如迷你精神状态检查(MMSE)和蒙特利尔认知评估(MoCA)。这些传统的测试通常以临床为基础,包括一系列的问题和任务,以评估短期记忆、注意力、重复和定向。传统的检测依赖于神经学家的经验和专业水平来提供和评估,结果通常受患者年龄(可能出现与年龄相关的正常认知衰退)和教育水平的影响。”
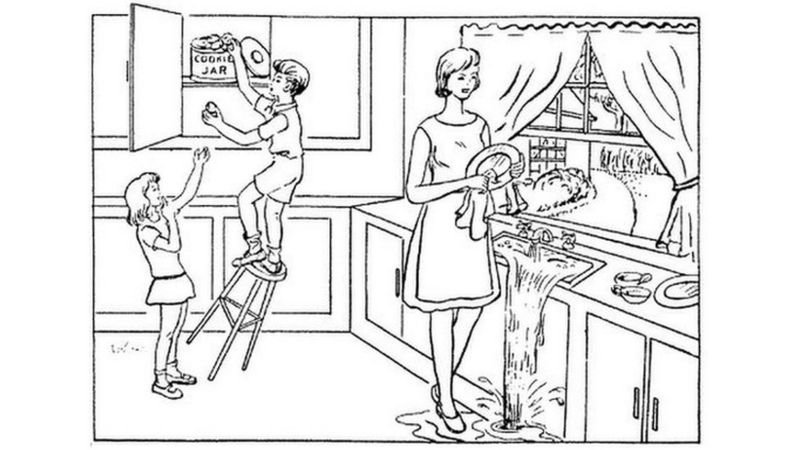
Alkenani说,随着痴呆症的发展,一个人的语言理解能力和语言复杂性会下降。“痴呆症的严重程度与有限的词汇量和词汇重复的增加有关,这给了我们可以作为语言的模式。生物标记物随着痴呆的发展。我们的研究分析了来自DementiaBank的语言样本。DementiaBank是一个大型开源数据库,收集了患有不同阶段认知障碍和痴呆症的人的语言样本,这些人完成了著名的“饼干盗窃”图片描述任务。”
在这项研究中,研究人员引入了一些新的单词和语法特征,以及之前建立的特征,以训练机器学习分类器来识别MCI和AD的语言生物标记。他们研究了236个疑似AD患者的语言样本,43个轻度认知障碍患者的语言样本,21个疑似AD患者的语言样本,以及243个健康人的语言样本。
“我们发现,与健康成年人相比,痴呆症患者在痴呆过程中倾向于使用更少的名词,而更多的动词、代词和形容词。”例如,我们发现名词与动词的比例和动词与名词的比例在区分AD和MCI与健康人方面是很重要的,”Alkenani解释道。“这很有趣,因为之前的研究表明,名词和动词是在大脑的不同区域学习和激活的,这些区域可以与大脑中最先受到痴呆症影响的区域相匹配,从而有助于早期干预。”
Alkenani说,这项研究被认为是第一个通过机器学习模型准确、自动地将AD、MCI和PoAD分类的研究。“我们探索了单词和语法模式,并将这些模式在所有阶段进行了关联,以突出最强的关联。我们的最终目标是开发一种会话代理或聊天机器人这可以用来远程促进早期痴呆的初步诊断,试图取代传统的筛查测试。”
这项研究发表在IEEE访问.
来源:昆士兰科技大学